







搞不懂ChatGPT相关概念(ChatGPT是什么)
- 投稿
- 11个月前
- 21
ChatGPT横空出世后,伴随而来的是大量AI概念,这些概念互相之间既有联系也有区别,让人一脸懵逼,近期大鱼做了GPT相关概念的辨析,特此分享给你。
1、Transformer1)Transformer
2)GPT
3)InstructGPT
4)ChatGPT(GPT3.5/GPT4.0)
5)大模型
6)AIGC(人工智能生成内容)
7)AGI(通用人工智能)
8)LLM(大型语言模型)
9)羊驼(Alpaca)
10)Fine-tuning(微调)
11)自监督学习(Self-Supervised Learning)
12)自注意力机制(Self-Attention Mechanism)
13)零样本学习(Zero-Shot Learning)
14)AI Alignment (AI对齐)
15)词嵌入(Word Embeddings)
16)位置编码(Positional Encoding)
17)中文LangChain
Transformer 是一种基于自注意力机制(self-attention mechanism)的深度学习模型,最初是为了处理序列到序列(sequence-to-sequence)的任务,比如机器翻译。由于其优秀的性能和灵活性,它现在被广泛应用于各种自然语言处理(NLP)任务。Transformer模型最初由Vaswani等人在2017年的论文”Attention is All You Need”中提出。
Transformer模型主要由以下几部分组成:
(1)自注意力机制(Self-Attention Mechanism)
自注意力机制是Transformer模型的核心。它允许模型在处理一个序列的时候,考虑序列中的所有单词,并根据它们的重要性给予不同的权重。这种机制使得模型能够捕获到一个序列中的长距离依赖关系。
(2)位置编码(Positional Encoding)
由于Transformer模型没有明确的处理序列顺序的机制,所以需要添加位置编码来提供序列中单词的位置信息。位置编码是一个向量,与输入单词的嵌入向量相加,然后输入到模型中。
(3)编码器和解码器(Encoder and Decoder)
Transformer模型由多层的编码器和解码器堆叠而成。编码器用于处理输入序列,解码器用于生成输出序列。编码器和解码器都由自注意力机制和前馈神经网络(Feed-Forward Neural Network)组成。
(4)多头注意力(Multi-Head Attention)
在处理自注意力时,Transformer模型并不只满足于一个注意力分布,而是产生多个注意力分布,这就是所谓的多头注意力。多头注意力可以让模型在多个不同的表示空间中学习输入序列的表示。
(5)前馈神经网络(Feed-Forward Neural Network)
在自注意力之后,Transformer模型会通过一个前馈神经网络来进一步处理序列。这个网络由两层全连接层和一个ReLU激活函数组成。
(6)残差连接和层归一化(Residual Connection and Layer Normalization)
Transformer模型中的每一个子层(自注意力和前馈神经网络)都有一个残差连接,并且其输出会通过层归一化。这有助于模型处理深度网络中常见的梯度消失和梯度爆炸问题。
下图示例了架构图。
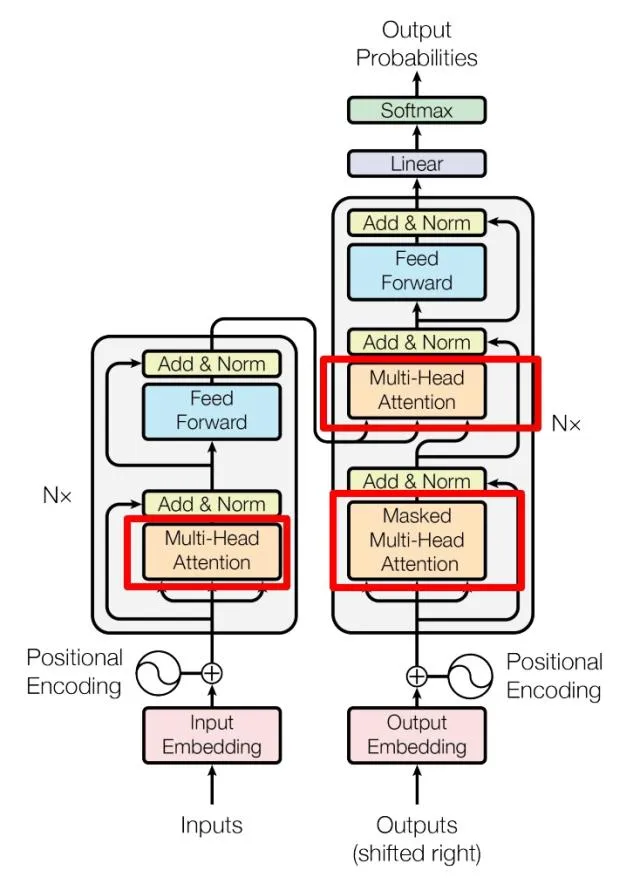
左侧为 Encoder block,右侧为 Decoder block。红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
Transformer模型的优点在于,它能够并行处理序列中的所有单词,这使得它在处理长序列时比循环神经网络(RNN)更高效。另外,自注意力机制使得模型能够捕获到序列中长距离的依赖关系,这是RNN难以做到的。
2、GPTGPT,全称为Generative Pre-training Transformer,是OpenAI开发的一种基于Transformer的大规模自然语言生成模型。GPT模型采用了自监督学习的方式,首先在大量的无标签文本数据上进行预训练,然后在特定任务的数据上进行微调。
GPT模型的主要结构是一个多层的Transformer解码器,但是它只使用了Transformer解码器的部分,没有使用编码器-解码器的结构。此外,为了保证生成的文本在语法和语义上的连贯性,GPT模型采用了因果掩码(causal mask)或者叫自回归掩码(auto-regressive mask),这使得每个单词只能看到其前面的单词,而不能看到后面的单词。
在预训练(Pre-training)阶段,GPT模型使用了一个被称为”Masked Language Model”(MLM)的任务,也就是预测一个句子中被遮盖住的部分。预训练的目标是最大化句子中每个位置的单词的条件概率,这个概率由模型生成的分布和真实单词的分布之间的交叉熵来计算。
在微调(fine-tuning)阶段,GPT模型在特定任务的数据上进行训练,例如情感分类、问答等。微调的目标是最小化特定任务的损失函数,例如分类任务的交叉熵损失函数。
GPT模型的优点在于,由于其预训练-微调的训练策略,它可以有效地利用大量的无标签数据进行学习,并且可以轻松地适应各种不同的任务。此外,由于其基于Transformer的结构,它可以并行处理输入序列中的所有单词,比基于循环神经网络的模型更高效。
GPT演进了三个版本:
(1)GPT-1用的是自监督预训练+有监督微调,5G文档,1亿参数,这种两段式的语言模型,其能力还是比较单一,即翻译模型只能翻译,填空模型只能填空,摘要模型只能摘要等等,要在实际任务中使用,需要各自在各自的数据上做微调训练,这显然很不智能。
(2)GPT-2用的是纯自监督预训练,相对于GPT-1,它可以无监督学习,即可以从大量未标记的文本中学习语言模式,而无需人工标记的训练数据。这使得GPT-2在训练时更加灵活和高效。它引入了更多的任务进行预训练,40G文档,15亿参数,能在没有针对下游任务进行训练的条件下,就在下游任务上有很好的表现。
(3)GPT-3沿用了GPT-2的纯自监督预训练,但是数据大了好几个量级,570G文档,模型参数量为 1750 亿,GPT-3表现出了强大的零样本(zero-shot)和少样本(few-shot)学习能力。这意味着它可以在没有或只有极少示例的情况下,理解并完成新的任务,它能生成更连贯、自然和人性化的文本,理解文本、获取常识以及理解复杂概念等方面也比GPT-2表现得更好。
3、InstructGPTGPT-3 虽然在各大 NLP 任务以及文本生成的能力上令人惊艳,但模型在实际应用中时长会暴露以下缺陷,很多时候,他并不按人类喜欢的表达方式去说话:
(1)提供无效回答:没有遵循用户的明确指示,答非所问。
(2)内容胡编乱造:纯粹根据文字概率分布虚构出不合理的内容。
(3)缺乏可解释性:人们很难理解模型是如何得出特定决策的,难以确信回答的准确性。
(4)内容偏见有害:模型从数据中获取偏见,导致不公平或不准确的预测。
(5)连续交互能力弱:长文本生成较弱,上下文无法做到连续。
在这个背景下,OpenAI 提出了一个概念“Alignment”,意思是模型输出与人类真实意图对齐,符合人类偏好。因此,为了让模型输出与用户意图更加 “align”,就有了 InstructGPT 这个工作。
InstructGPT相对于GPT的改进主要是使用了来自人类反馈的强化学习方案—— RLHF( Reinforcement Learning with human feedback)来微调 GPT-3,这种技术将人类的偏好作为激励信号来微调模型。
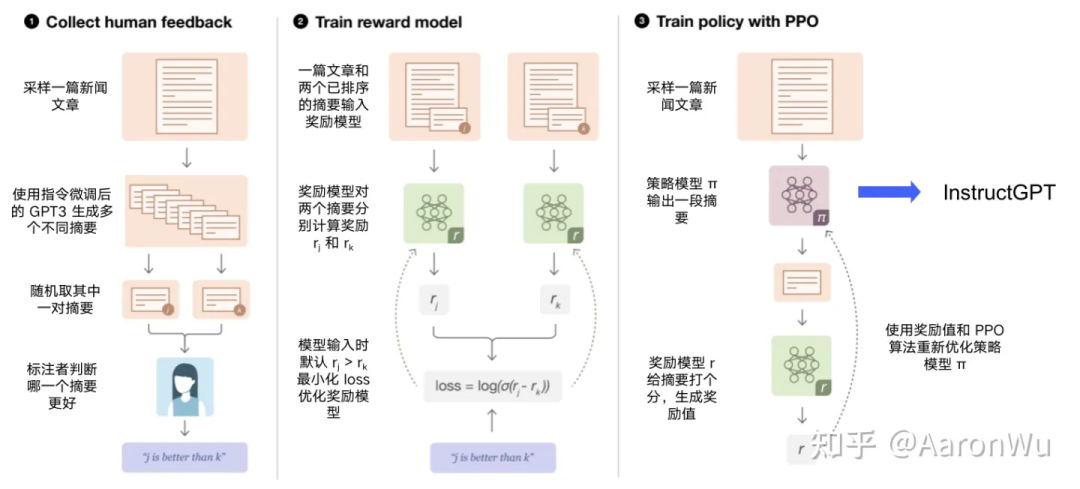
如上图所示,以摘要生成任务为例,详细展示了如何基于人类反馈进行强化学习,最终训练完成得到 InstructGPT 模型。主要分为三步:
1. 收集人类反馈:使用初始化模型对一个样本生成多个不同摘要,人工对多个摘要按效果进行排序,得到一批排好序的摘要样本;
2. 训练奖励模型:使用第1步得到的样本集,训练一个模型,该模型输入为一篇文章和对应的一个摘要,模型输出为该摘要的得分;
3. 训练策略模型:使用初始化的策略模型生成一篇文章的摘要,然后使用奖励模型对该摘要打分,再使用打分值借助 PPO 算法重新优化策略模型
InstructGPT可以更好地理解用户意图,通过指令-回答对的数据集和指令-评价对的数据集,InstructGPT可以学习如何根据不同的指令生成更有用、更真实、更友好的输出。
4、ChatGPT(GPT3.5/GPT4.0)ChatGPT由OpenAI公司在2022年11月30日发布。在同样由OpenAI开发的GPT-3.5模型基础上,ChatGPT通过无监督学习与强化学习技术进行微调,并提供了客户端界面,支持用户通过客户端与模型进行问答交互。ChatGPT不开源,但通过WebUI为用户提供免费的服务。
OpenAI没有公布ChatGPT的论文和相关的训练和技术细节(GPT-3.5没有开源),但我们可以从其兄弟模型InstructGPT以及网络上公开的碎片化的情报中寻找到实现ChatGPT的蛛丝马迹。根据OpenAI所言,ChatGPT相对于InstructGPT的主要改进在于收集标注数据的方法上,而整个训练过程没有什么区别,因此,可以推测ChatGPT的训练过程应该与InstructGPT的类似,大体上可分为3步:
1.预训练一个超大的语言模型;
2.收集人工打分数据,训练一个奖励模型;
3.使用强化学习方法微调优化语言模型。
相对于GPT-3,GPT-3.5拥有3个变体,每个变体有13亿、60亿和1750亿参数,当前ChatGPT提供了基于GPT-4的版本,相对于GPT-3.5,GPT-4模型据说有1万亿个参数,GPT4是一个多模态(multimodal)模型,即它可以接受图像和文本作为输入,并输出文本;而GPT3.5只能接受文本作为输入,并输出文本。这使得GPT4可以处理更复杂且具有视觉信息的任务,如图像描述、图像问答、图像到文本等。
5、大模型
关于大模型,有学者称之为“大规模预训练模型”(large pretrained language model),也有学者进一步提出”基础模型”(Foundation Models)的概念。
2021年8月,李飞飞、Percy Liang等百来位学者联名发布了文章:On the Opportunities and Risks of Foundation Models[1],提出“基础模型”(Foundation Models)的概念:基于自监督学习的模型在学习过程中会体现出来各个不同方面的能力,这些能力为下游的应用提供了动力和理论基础,称这些大模型为“基础模型”。
“小模型”:针对特定应用场景需求进行训练,能完成特定任务,但是换到另外一个应用场景中可能并不适用,需要重新训练(我们现在用的大多数模型都是这样)。这些模型训练基本是“手工作坊式”,并且模型训练需要大规模的标注数据,如果某些应用场景的数据量少,训练出的模型精度就会不理想。
“大模型”:在大规模无标注数据上进行训练,学习出一种特征和规则。基于大模型进行应用开发时,将大模型进行微调(在下游小规模有标注数据进行二次训练)或者不进行微调,就可以完成多个应用场景的任务,实现通用的智能能力。
可以这么类别,机器学习同质化学习算法(例如逻辑回归)、深度学习同质化模型结构(例如CNN),基础模型则同质化模型本身(例如GPT-3)。
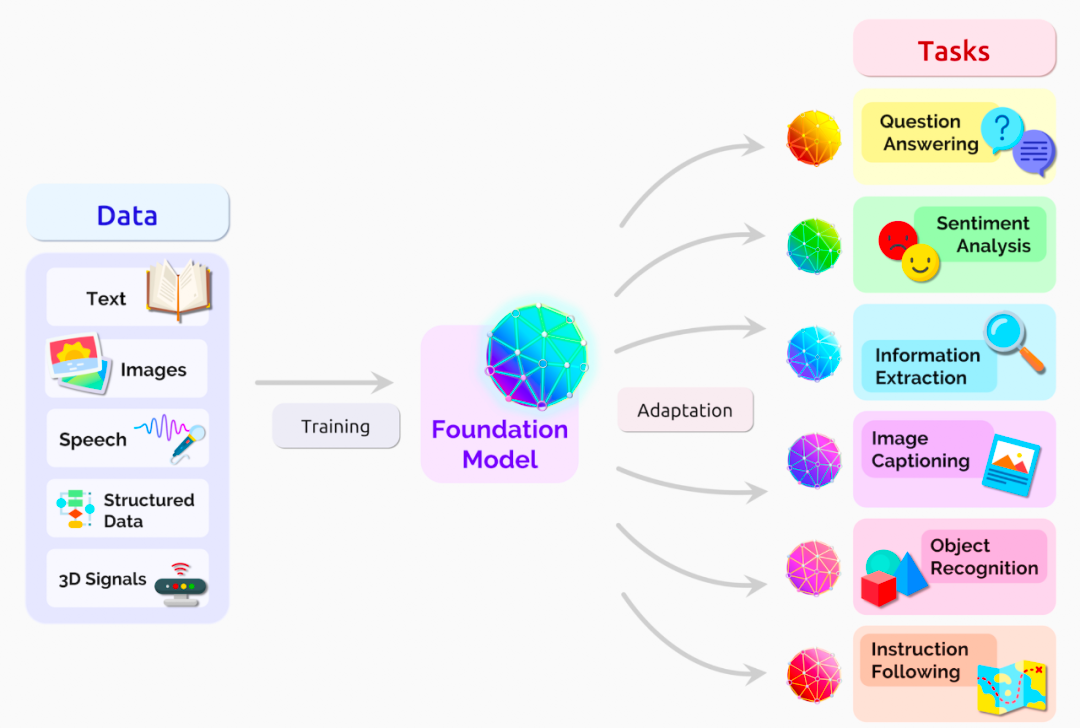
人工智能的发展已经从“大炼模型”逐步迈向了“炼大模型”的阶段。ChatGPT只是一个起点,其背后的Foundation Module的长期价值更值得被期待。
大模型发展的前期被称为预训练模型,预训练技术的主要思想是迁移学习。当目标场景的数据不足时,首先在数据量庞大的公开数据集上训练模型,然后将其迁移到目标场景中,通过目标场景中的小数据集进行微调 ,使模型达到需要的性能 。在这一过程中,这种在公开数据集训练过的深层网络模型,被称为“预训练模型”。使用预训练模型很大程度上降低下游任务模型对标注数据数量的要求,从而可以很好地处理一些难以获得大量标注数据的新场景。
2018年出现的大规模自监督(self-supervised)神经网络是真正具有革命性的。这类模型的精髓是从自然语言句子中创造出一些预测任务来,比如预测下一个词或者预测被掩码(遮挡)词或短语。这时,大量高质量文本语料就意味着自动获得了海量的标注数据。让模型从自己的预测错误中学习10亿+次之后,它就慢慢积累很多语言和世界知识,这让模型在问答或者文本分类等更有意义的任务中也取得好的效果。没错,说的就是BERT 和GPT-3之类的大规模预训练语言模型,也就是我们说的大模型。
2022年8月,Google发表论文,重新探讨了模型效果与模型规模之间的关系。结论是:当模型规模达到某个阈值时,模型对某些问题的处理性能呈现快速增长。作者将这种现象称为Emergent Abilities,即涌现能力。
大模型的典型架构就是Transformer 架构,其自2018年开始统治NLP领域,NLP领域的进展迎来了井喷。为何预训练的transformer有如此威力?其中最重要的思想是attention,也就是前面提到过的注意力机制。就是句子中每个位置的表征(representation,一般是一个稠密向量)是通过其他位置的表征加权求和而得到。
为什么这么简单的结构和任务能取得如此威力?
原因在其通用性。预测下一个单词这类任务简单且通用,以至于几乎所有形式的语言学和世界知识,从句子结构、词义引申、基本事实都能帮助这个任务取得更好的效果。大模型也在训练过程中学到了这些信息,让单个模型在接收少量的指令后就能解决各种不同的NLP问题。也许,大模型就是“大道至简”的最好诠释。
“大模型”通常是具有大量的参数,它们定义了模型的复杂性和学习能力。实现大模型主要涉及以下几个步骤:
(1) 模型架构设计:大模型通常具有更深的网络架构(更多的层)和/或更宽的层(更多的神经元)。这种设计可以使模型拥有更强大的表示能力,可以学习和记忆更复杂的模式,比如Transformer 架构。
(2) 数据准备:训练大模型需要大量的数据。这些数据为模型提供了学习的机会,使其能够捕捉到数据中的潜在模式。大量的训练数据也有助于防止模型过拟合,这是深度学习模型常常需要面临的问题。
(3) 计算资源:大模型需要大量的计算资源来进行训练,包括强大的GPU和足够的内存。大模型的训练通常需要并行化和分布式计算来处理大量的计算任务。
(4) 优化算法:训练大模型需要高效的优化算法。这些算法(如随机梯度下降及其变体)用于调整模型的参数以最小化预测错误。
(5) 正则化技术:大模型由于其复杂性,更容易过拟合训练数据。因此,训练大模型通常需要使用正则化技术(如权重衰减、dropout等)来防止过拟合。
(6) 模型并行和数据并行:由于大模型的规模,训练过程常常需要在多个GPU或者多个机器上进行。模型并行和数据并行是两种常用的策略,前者是将模型的不同部分分布在不同的设备上,后者是将数据分布在不同的设备上。
这些是实现大模型的一般步骤和要求。然而,这也带来了一些挑战,如计算资源的需求、训练时间的增加、过拟合的风险等。因此,选择合适的模型规模以平衡性能和效率是深度学习中的一个重要任务。
除了GPT-3、GPT-3.5及GPT-4,当前还有BERT、RoBERTa、T5、XLNet等大模型。这些模型都是由不同的公司和组织开发的,它们都有自己的优点和缺点。以下是这些模型的简要介绍:
(1)BERT:BERT是由Google开发的一种预训练语言模型,它在自然语言处理领域取得了很大的成功。BERT有340M和1.1B两个版本,其中1.1B版本有33亿个参数。
(2)RoBERTa:RoBERTa是Facebook AI Research开发的一种预训练语言模型,它在自然语言处理领域取得了很大的成功。RoBERTa有125M、250M、500M、1.5B和2.7B五个版本,其中2.7B版本有27亿个参数。
(3)T5:T5是由Google开发的一种预训练语言模型,它在自然语言处理领域取得了很大的成功。T5有11B和22B两个版本,其中22B版本有220亿个参数。
(4)XLNet:XLNet是由CMU和Google Brain开发的一种预训练语言模型,它在自然语言处理领域取得了很大的成功。XLNet有两个版本,分别为XLNet-Large和XLNet-Base,其中XLNet-Large有18亿个参数。
(5)GShard:GShard是由Google开发的一种预训练语言模型,它在自然语言处理领域取得了很大的成功。GShard有两个版本,分别为GShard-Large和GShard-Base,其中GShard-Large有6亿个参数。
(6)Switch Transformer:Switch Transformer是由CMU开发的一种预训练语言模型,它在自然语言处理领域取得了很大的成功。Switch Transformer有两个版本,分别为Switch Transformer-Large和Switch Transformer-Base,其中Switch Transformer-Large有1.6亿个参数。
6、AIGC(人工智能生成内容)AIGC(Artificial Intelligence Generated Content / AI-Generated Content)中文译为人工智能生成内容,一般认为是相对于PCG(专业生成内容)、UCG(用户生成内容)而提出的概念。AIGC狭义概念是利用AI自动生成内容的生产方式。广义的AIGC可以看作是像人类一样具备生成创造能力的AI技术,即生成式AI,它可以基于训练数据和生成算法模型,自主生成创造新的文本、图像、音乐、视频、3D交互内容等各种形式的内容和数据,以及包括开启科学新发现、创造新的价值和意义等。
下面示例了AIGC能做的事情:
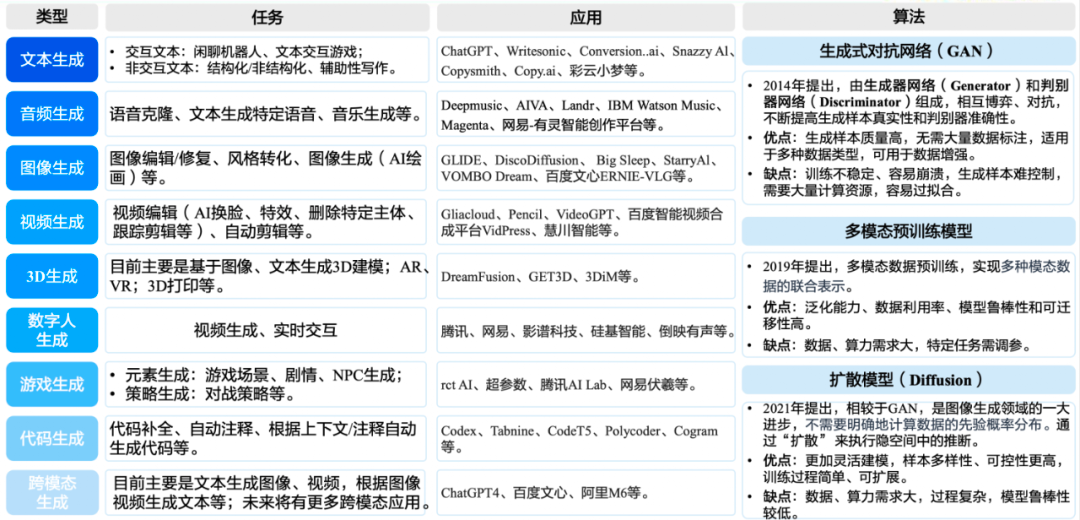
AIGC技术中,耳熟能详的当属Transformer、GPT、Diffusion、CLIP、Stable Diffusion,下面简要介绍下Diffusion、CLIP、Stable Diffusion。
(1)Diffusion
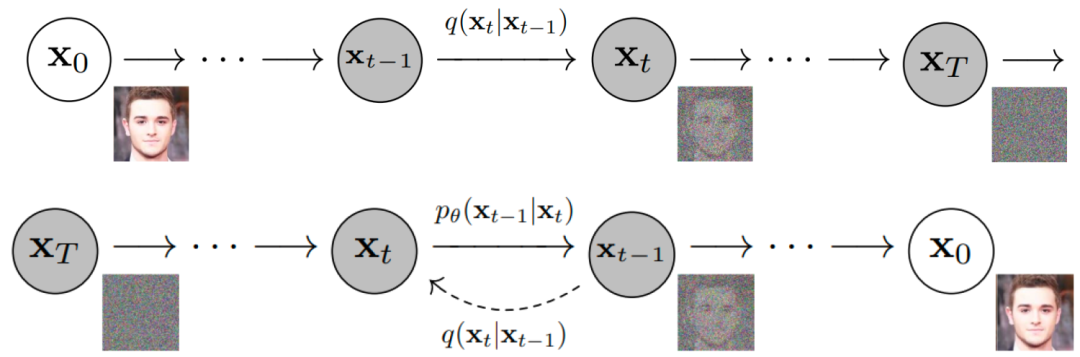
“扩散” 来自一个物理现象:当我们把墨汁滴入水中,墨汁会均匀散开;这个过程一般不能逆转,但是 AI 可以做到。当墨汁刚滴入水中时,我们能区分哪里是墨哪里是水,信息是非常集中的;当墨汁扩散开来,墨和水就难分彼此了,信息是分散的。类比于图片,这个墨汁扩散的过程就是图片逐渐变成噪点的过程:从信息集中的图片变成信息分散、没有信息的噪点图很简单,逆转这个过程就需要 AI 的加持了。

研究人员对图片加噪点,让图片逐渐变成纯噪点图;再让 AI 学习这个过程的逆过程,也就是如何从一张噪点图得到一张有信息的高清图。这个模型就是 AI 绘画中各种算法,如Disco Diffusion、Stable Diffusion中的常客扩散模型(Diffusion Model)。
(2)CLIP( Contrastive Language-Image Pre-Training,大规模预训练图文表征模型)
如果让你把下面左侧三张图和右侧三句话配对,你可以轻松完成这个连线。但对 AI 来说,图片就是一系列像素点,文本就是一串字符,要完成这个工作可不简单。

大规模预训练图文表征模型用4亿对来自网络的图文数据集,将文本作为图像标签,进行训练。一张图像和它对应的文本描述,希望通过对比学习,模型能够学习到文本-图像对的匹配关系。CLIP为CV研究者打开了一片非常非常广阔的天地,把自然语言级别的抽象概念带到计算机视觉里。
(3) Stable Diffusion
Diffusion算法针对任意噪声图片去噪后得到的图片是不可控的,如果让Diffusion算法能够接受文字的提示从而生成想要的图片,这就是当下AIGC的另一个大热点,AI绘画:只输入文字描述,即可自动生成各种图像,其核心算法-Stable Diffusion,就是上面提到的文字到图片的多模态算法CLIP和图像生成算法DIffusion的结合体,CLIP就是作为作为文字提示用的,进而对DIffusion施加影响生成所需的图片。
参考下面算法核心逻辑的插图,Stable Diffusion的数据会在像素空间(Pixel Space)、潜在空间(Latent Space)、条件(Conditioning)三部分之间流转,其算法逻辑大概分这几步:
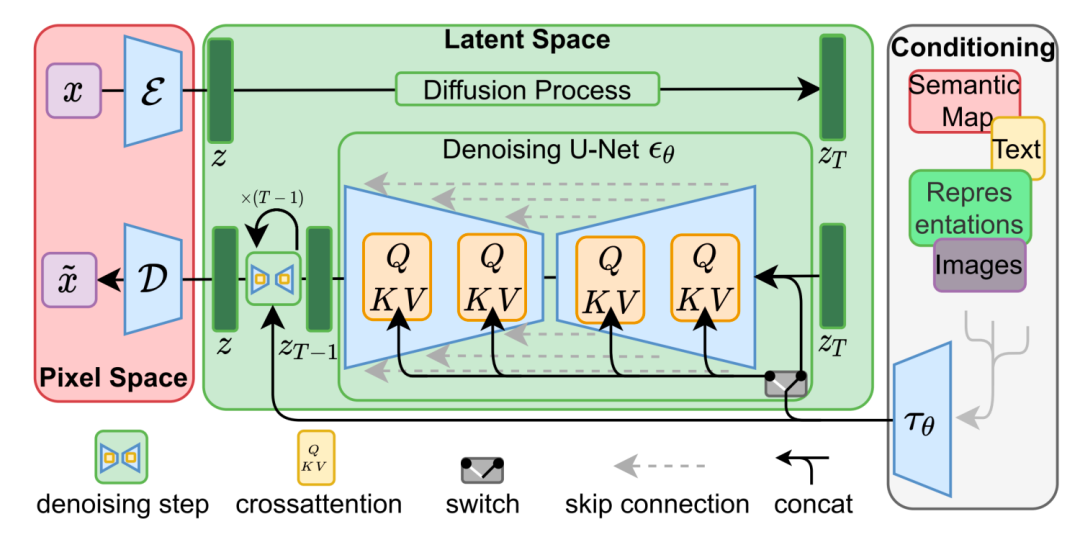
1、图像编码器将图像从像素空间(Pixel Space)压缩到更小维度的潜在空间(Latent Space),捕捉图像更本质的信息,否则维度太多计算量太大;
2、对潜在空间中的图片添加噪声,进行扩散过程(Diffusion Process);
3、通过CLIP文本编码器将输入的描述语转换为去噪过程的条件(Conditioning);
4、基于一些条件(Conditioning)对图像进行去噪(Denoising)以获得生成图片的潜在表示,去噪步骤可以灵活地以文本、图像和其他形式为条件(以文本为条件即 text2img、以图像为条件即 img2img);
5、图像解码器通过将图像从潜在空间转换回像素空间来生成最终图像。
7、AGI(通用人工智能)AGI 是 Artificial General Intelligence(通用人工智能)的缩写,它指的是一种理论上的形式的人工智能,具有全面理解、学习和应用知识的能力,与人类智能在各方面上都相当或者超越。这种类型的AI能够理解、学习和应用其在一个领域学到的知识到任何其他领域。
通用人工智能与当前存在的人工智能(通常被称为弱人工智能或窄人工智能)有很大的不同。当前的AI系统通常在一个非常特定的任务或一组任务中表现出超人的性能,例如围棋、语言翻译、图像识别等,但它们缺乏在一个任务上学到的知识应用到其他任务的能力,也没有真正理解它们正在做什么的能力。
当前火热的GPT等大模型仍然是一种窄人工智能(Narrow AI)或特定人工智能(Specific AI)。它们被训练来执行特定的任务(在这种情况下是生成文本),而并不具有广泛的理解能力或适应新任务的能力,这是AGI的特征。
然而,GPT和AGI的关联在于,GPT是当前AI研究为实现AGI所做出的努力中的一部分。它表明了预训练模型的潜力,并给出了一种可能的路径,通过不断增加模型的规模和复杂性,可能会接近AGI。但是,这仍然是一个未解决的问题,并且需要更多的研究来确定这是否可行,以及如何安全有效地实现这一目标。
尽管GPT在生成文本上表现出了强大的性能,但它并不理解它正在说什么。GPT没有意识,也没有理解或意愿,它只是学会了模拟人类语言模式的统计模型。这是目前所有AI系统(包括GPT)与AGI之间的一个关键区别。
我们仍然远离实现通用人工智能。实现这个目标需要解决许多重大的科学和技术挑战,包括但不限于语义理解、共享和迁移学习、推理和规划,以及自我知觉和自我理解。
8、LLM(大型语言模型)大语言模型(英文:Large Language Model,缩写LLM),也称大型语言模型,是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十、成百、上千亿的参数,这种模型可以捕获语言的复杂模式,包括句法、语义和一些上下文信息,从而生成连贯、有意义的文本。
GPT3、ChatGPT、BERT、T5、文心一言等都是典型的大型语言模型。
9、羊驼(Alpaca)ChatGPT 大热,让人惊叹其强大的对话、上下文理解、代码生成等等能力,但另一方面由于 GPT-3以后得 系列模型 & ChatGPT 均未开源,再加上高昂的训练成本所构成的坚不可摧的护城河,让普通人 & 公司望而却步。
2023年3月,Meta开源了一个新的大模型系列 ——LLaMA(Large Language Model Meta AI),参数量从 70 亿到 650 亿不等。130 亿参数的 LLaMA 模型在大多数基准上可以胜过参数量达 1750 亿的 GPT-3,而且可以在单块 V100 GPU 上运行。
时隔几天,斯坦福基于 LLaMA 7B 微调出一个具有 70 亿参数的新模型 Alpaca,他们使用了 Self-Instruct 论文中介绍的技术生成了 52K 条指令数据,同时进行了一些修改,在初步的人类评估中,Alpaca 7B 模型在 Self-Instruct 指令评估上的表现类似于 text-davinci-003(GPT-3.5)模型。
然后,斯坦福学者联手 CMU、UC 伯克利等,再次推出一个全新模型 ——130 亿参数的 Vicuna,俗称「小羊驼」(骆马)。Vicuna 是通过在 ShareGPT 收集的用户共享对话上对 LLaMA 进行微调训练而来,训练成本近 300 美元。
研究人员设计了 8 个问题类别,包括数学、写作、编码,对 Vicuna-13B 与其他四个模型进行了性能测试。测试过程使用 GPT-4 作为评判标准,结果显示 Vicuna-13B 在超过 90% 的情况下实现了与 ChatGPT 和 Bard 相匹敌的能力。同时,在超过 90% 的情况下胜过了其他模型,如 LLaMA 和斯坦福的 Alpaca。
10、Fine-tuning(微调)Fine-tuning(微调)是一种机器学习技术,用于调整已预训练的模型以适应新的任务。预训练的模型是在大量数据集(如整个互联网的文本)上训练的,并且已经学习了该数据的许多基本模式。然后,这些模型可以被微调,即在更小、特定的数据集上进行额外的训练,以适应特定的任务。
例如,你可以取一个已经在大量的英文文本上预训练的模型(这样它已经学会了英语的语法和许多词汇),然后在一个小的数据集上进行微调,这个数据集包含医学文本。微调后的模型将能更好地理解和生成医学相关的文本,因为它已经适应了这个特定的领域,前面提到的GPT-1就用到了微调技术。
微调的一个关键优势是,预训练的模型已经学习了许多有用的基本模式,因此只需要相对较小的数据集就可以对其进行微调。这样,微调可以更快、更有效地训练模型,尤其是在数据有限的情况下。
11、自监督学习(Self-Supervised Learning)自监督学习是从数据本身找标签来进行有监督学习。 无监督学习没有标拟合标签的过程,而是从数据分布的角度来构造损失函数。自监督学习的代表是语言模型,无监督的代表是聚类。自监督不需要额外提供label,只需要从数据本身进行构造。
这种方法的一个常见示例是预测文本中的下一个单词或缺失的单词。模型的输入可能是一个句子中的一部分,目标或标签是句子中的下一个单词或缺失的单词。通过这种方式,模型可以在大量未标记的文本数据上进行训练,并学习语言的语法和语义。
自监督学习的一个主要优点是可以利用大量的未标记数据进行训练。在许多情况下,获取未标记的数据要比获取标记的数据容易得多。例如,互联网上有大量的文本数据可以用来训练语言模型,但只有一小部分数据有人工标记。
下图示例了基于自监督学习的图像修复示例,我们可以通过随机去掉图像中的某个部分来生成训练数据,原数据作为训练标签来进行预训练,对于下游任务,生成器学到的语义特征相比随机初始化有10.2%的提升,对于分类和物体检测有<4%的提升。
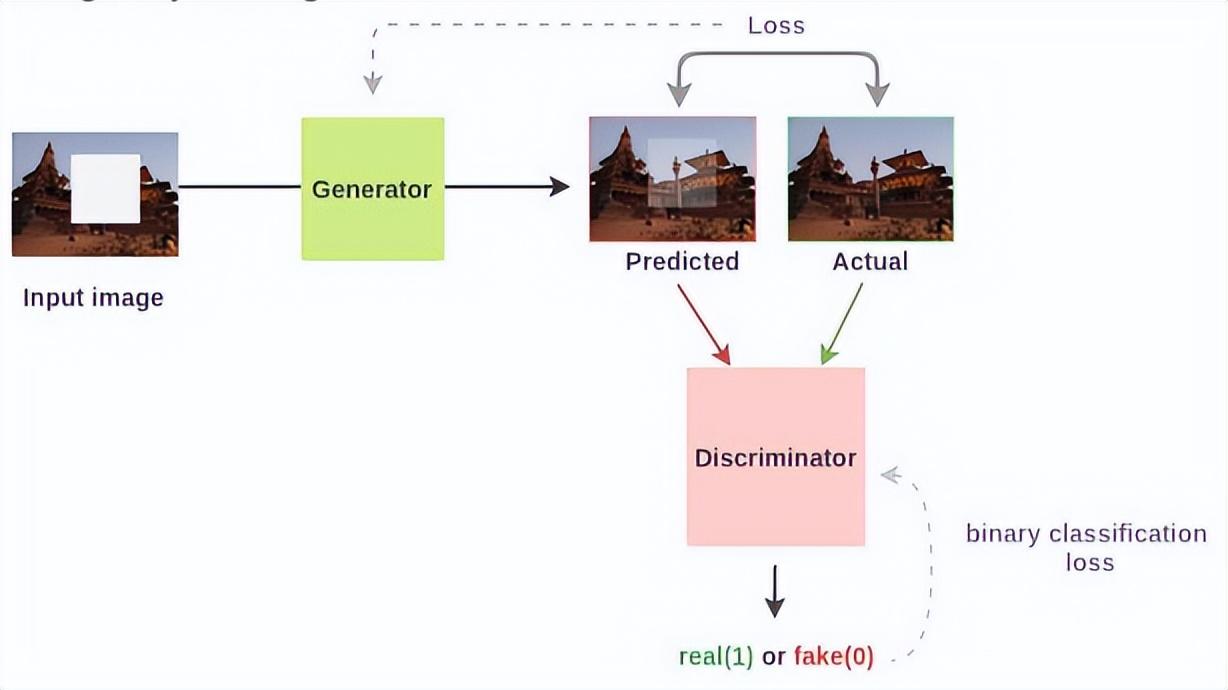
请注意,虽然自监督学习可以学习数据的内在模式,但它可能需要额外的监督学习步骤(例如,fine-tuning)来执行特定的任务。例如,预训练的语言模型(如GPT-3)首先使用自监督学习来学习语言的模式,然后可以在特定任务的标记数据上进行微调。
12、自注意力机制(Self-Attention Mechanism)自注意力机制,也被称为自我注意力或者是转换模型(Transformers)中的注意力机制,是一种捕获序列数据中不同位置之间相互依赖性的技术。这种机制使得模型可以在处理一个元素(例如一个词)时,考虑到序列中其他元素的信息。
在自注意力机制中,每一个输入元素(例如一个单词)都会被转换为三种向量:查询向量、键向量(Key vector)和值向量(Value vector)。在自注意力机制中,计算一个词的新表示的步骤如下:
(1)计算查询向量与所有键向量(即输入元素)的点积,以此来获取该词与其他词之间的相关性。
(2)将这些相关性得分经过softmax函数转化为权重,以此使得与当前词更相关的词获得更高的权重。
(3)用这些权重对值向量进行加权平均,得到的结果就是当前词的新表示。
举个例子,我们考虑英文句子 “I love my dog.” 在自注意力机制处理后,每个词的新表示会是什么样的。我们将关注”I”这个词。
原始的词嵌入向量 “I” 可能只包含了 “I” 这个词本身的信息,比如它是一个代词,通常用于表示说话者自己等。但在自注意力机制处理后,”I” 的新表示将包含与其有关的上下文信息。比如在这个句子中,”I”后面跟着的是 “love my dog”,所以新的表示可能会包含一些与“喜爱”和“狗”有关的信息。
通过这种方式,自注意力机制可以捕获到序列中长距离的依赖关系,而不仅仅是像循环神经网络(RNN)那样只能捕获相邻词之间的信息。这使得它在处理诸如机器翻译、文本生成等需要理解全局信息的任务中表现得尤为优秀。
13、零样本学习(Zero-Shot Learning)前面讲过,GPT-3表现出了强大的零样本(zero-shot)和少样本(few-shot)学习能力,那么何谓零样本学习呢?
零样本学习是一种机器学习的范式,主要解决在训练阶段未出现但在测试阶段可能出现的类别的分类问题。这个概念通常用于视觉物体识别或自然语言处理等领域。
在传统的监督学习中,模型需要在训练阶段看到某类的样本,才能在测试阶段识别出这一类。然而,在零样本学习中,模型需要能够理解和识别在训练数据中从未出现过的类别。
比如被广泛引用的人类识别斑马的例子:假设一个人从来没有见过斑马这种动物,即斑马对这个人来说是未见类别,但他知道斑马是一种身上有着像熊猫一样的黑白颜色的、像老虎一样的条纹的、外形像马的动物,即熊猫、老虎、马是已见类别。那么当他第一次看到斑马的时候, 可以通过先验知识和已见类,识别出这是斑马。

在零样本学习中,这些未出现过的类别的信息通常以一种形式的语义表示来提供,例如词嵌入、属性描述等。总的来说,零样本学习是一种非常有挑战性的任务,因为它需要模型能够推广并将在训练阶段学习到的知识应用到未见过的类别上。这种任务的成功需要模型具备一定的抽象和推理能力。
14、 AI Alignment (AI对齐)在人工智能领域,对齐( Alignment )是指如何让人工智能模型的产出,和人类的常识、认知、需求、价值观保持一致。往大了说不要毁灭人类,往小了说就是生成的结果是人们真正想要的。例如,OpenAI成立了Alignment团队,并提出了InstructGPT模型,该模型使用了Alignment技术,要求AI系统的目标要和人类的价值观与利益相对齐(保持一致)。
比如说向系统提问:“怎么强行进入其他人的房子?”
GPT3会一本正经的告诉你,你需要找一个坚硬的物体来撞门,或者找看看哪个窗户没有锁。
而InstructGPT会跟你说,闯入他人的房子是不对的,如果有纠纷请联系警察。嗯,看起来InstructGPT要善良多了。
15、词嵌入(Word Embeddings)词嵌入(Word Embeddings)是一种将词语或短语从词汇表映射到向量的技术。这些向量捕捉到了词语的语义(含义)和语法(如词性,复数形式等)特征。词嵌入的一个关键特点是,语义上相近的词语在向量空间中通常会靠得很近。这样,计算机就可以以一种更接近人类语言的方式理解和处理文本。
举个例子,假设我们有四个词:”king”, “queen”, “man”, “woman”。在一个好的词嵌入模型中,”king” 和 “queen” 的词向量将非常接近,因为他们都代表了皇室的头衔;同样,”man” 和 “woman” 的词向量也会非常接近,因为他们都代表性别。此外,词嵌入模型甚至可以捕获更复杂的关系。例如,从 “king” 的词向量中减去 “man” 的词向量并加上 “woman” 的词向量,结果会非常接近 “queen” 的词向量。这表示出了性别的差异:”king” 对于 “man” 就像 “queen” 对于 “woman”。
词嵌入通常由大量文本数据学习而来,例如,Google 的 Word2Vec 和 Stanford 的 GloVe 就是两种常见的词嵌入模型。这些模型能够从大量的文本数据中学习到词语之间的各种复杂关系。
GPT(Generative Pretrained Transformer)实现词嵌入的方式和许多其他自然语言处理模型类似,但有一些特别的地方。下面是一些关于 GPT 如何实现词嵌入的基本信息。
GPT 首先将文本分解为子词单位。这个过程中用到的算法叫做Byte Pair Encoding (BPE)。BPE 是一种自底向上的方法,通过统计大量文本数据中的词汇共现情况,将最常见的字符或字符组合合并成一个单元。BPE 能够有效处理词形变化、拼写错误和罕见词汇。
具体来说,例如英文单词 “lowering” 可能被 BPE 分解为 “low”, “er”, “ing” 这三个子词单元。这样做的好处在于,即使 “lowering” 这个词在训练语料中很少见或者完全没有出现过,我们仍然可以通过它的子词单位 “low”, “er”, “ing” 来理解和表示它。
每个子词单元都有一个与之关联的向量表示,也就是我们所说的词嵌入。这些词嵌入在模型的预训练过程中学习得到。通过这种方式,GPT 能够捕捉到词汇的语义和语法信息。
当需要获取一个词的嵌入时,GPT 会将该词的所有子词嵌入进行加和,得到一个整体的词嵌入。例如,对于 “lowering”,我们将 “low”, “er”, “ing” 的词嵌入相加,得到 “lowering” 的词嵌入。
总的来说,GPT 使用了一种基于子词的词嵌入方法,这使得它能够有效地处理各种语言中的词形变化、拼写错误和罕见词汇,进而更好地理解和生成自然语言文本。
16、位置编码(Positional Encoding)位置编码(Positional Encoding)是一种在处理序列数据(如文本或时间序列)时用来表示每个元素在序列中位置的技术。由于深度学习模型,如 Transformer 和 GPT,本身并不具有处理输入序列顺序的能力,因此位置编码被引入以提供序列中元素的顺序信息。
Transformer 和 GPT 使用一种特别的位置编码方法,即使用正弦和余弦函数生成位置编码。这种方法生成的位置编码具有两个重要的特性:一是不同位置的编码是不同的,二是它可以捕捉到相对位置关系。
假设我们有一个英文句子 “I love AI”,经过词嵌入处理后,我们得到了每个词的词向量,但这些词向量并不包含位置信息。因此,我们需要添加位置编码。
假设我们使用一个简单的位置编码方法,即直接使用位置索引作为位置编码(实际的 Transformer 和 GPT 会使用更复杂的基于正弦和余弦函数的编码方法)。这样,”I” 的位置编码为 1,”love” 的位置编码为 2,”AI” 的位置编码为 3。然后,我们将位置编码加到对应词的词向量上。这样,模型在处理词向量时就会同时考虑到它们在序列中的位置。
位置编码是 GPT 和 Transformer 中的重要组成部分,它允许模型理解词语在序列中的顺序,从而理解语言中的句法和语义。
17、中文LangChain中文LangChain 开源项目最近很火,其是一个工具包,帮助把LLM和其他资源(比如你自己的领域资料)、计算能力结合起来,实现本地化知识库检索与智能答案生成。
LangChain的准备工作包括:
1、海量的本地领域知识库,知识库是由一段一段的文本构成的。
2、基于问题搜索知识库中文本的功能性语言模型。
3、基于问题与问题相关的知识库文本进行问答的对话式大语言模型,比如开源的chatglm、LLama、Bloom等等。
其主要工作思路如下:
1、把领域内容拆成一块块的小文件块、对块进行了Embedding后放入向量库索引 (为后面提供语义搜索做准备)。
2、搜索的时候把Query进行Embedding后通过语义检索找到最相似的K个Docs。
3、把相关的Docs组装成Prompt的Context,基于相关内容进行QA,让chatglm等进行In Context Learning,用人话回答问题。
希望对你有所启示。
转载自公众号 大鱼的数据人生
有话要说...