

在flink中如何进行keyby窗口数据倾斜的优化
- 网赚资讯
- 1年前
- 3
在flink中如何进行keyby窗口数据倾斜的优化 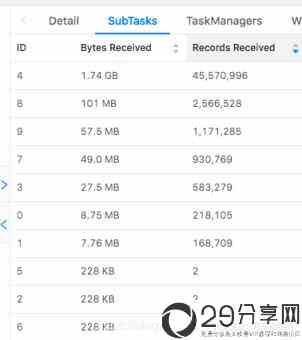
image 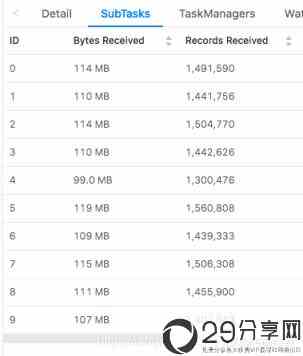
image
今天就跟大家聊聊有关在flink中如何进行keyby窗口数据倾斜的优化,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
在大数据处理领域,数据倾斜是一个非常常见的问题,我们就简单讲讲在flink中如何处理流式数据倾斜问题。
我们先来看一个可能产生数据倾斜的sql.
selectTUMBLE_END(proc_time,INTERVAL'1'MINUTE)aswinEnd,plat,count(*)aspvfromsource_kafka_tablegroupbyTUMBLE(proc_time,INTERVAL'1'MINUTE),plat
在这个sql里,我们统计一个网站各个端的每分钟的pv,从kafka消费过来的数据首先会按照端进行分组,然后执行聚合函数count来进行pv的计算。如果某一个端产生的数据特别大,比如我们的微信小程序端产生数据远远大于其他app端的数据,那么把这些数据分组到某一个算子之后,由于这个算子的处理速度跟不上,就会产生数据倾斜。
查看flink的ui,会看到如下的场景。
对于这种简单的数据倾斜,我们可以通过对分组的key加上随机数,再次打散,分别计算打散后不同的分组的pv数,然后在最外层再包一层,把打散的数据再次聚合,这样就解决了数据倾斜的问题。
优化后的sql如下:
selectwinEnd,split_index(plat1,'_',0)asplat2,sum(pv)from(selectTUMBLE_END(proc_time,INTERVAL'1'MINUTE)aswinEnd,plat1,count(*)aspvfrom(--最内层,将分组的key,也就是plat加上一个随机数打散selectplat||'_'||cast(cast(RAND()*100asint)asstring)asplat1,proc_timefromsource_kafka_table)groupbyTUMBLE(proc_time,INTERVAL'1'MINUTE),plat1)groupbywinEnd,split_index(plat1,'_',0)
在这个sql的最内层,将分组的key,也就是plat加上一个随机数打散,然后求打散后的各个分组(也就是sql中的plat1)的pv值,然后最外层,将各个打散的pv求和。
注意:最内层的sql,给分组的key添加的随机数,范围不能太大,也不能太小,太大的话,分的组太多,增加checkpoint的压力,太小的话,起不到打散的作用。在我的测试中,一天大概十几亿的数据量,5个并行度,随机数的范围在100范围内,就可以正常处理了。
修改后我们看到各个子任务的数据基本均匀了。
看完上述内容,你们对在flink中如何进行keyby窗口数据倾斜的优化有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注29分享网行业资讯频道,感谢大家的支持。
有话要说...