



数据分析软件排名(最新出炉的十大实用数据分析工具)
- 网赚杂谈
- 1年前
- 16
回首过去的2018,数据科学技术飞速发展,各种新工具,新语言层出不穷,人们处理数据、获取信息的能力可以说是呈爆炸性增长。
在这样的形势下,不论你是略有小成的数据科学家,还是刚刚入门的数据分析新手,都很有必要了解目前最前沿的技术工具。毕竟磨刀不负砍柴功嘛。
日前,供职于全球领先的社交游戏服务提供商 Zynga 的首席数据科学家 Ben Weber 给我们推荐了他眼中的2018年十大实用数据科学工具,让我们一起来看看吧!
1. Bookdown
Bookdown是一个开源的 R 代码库,它可以把用 R Markdown 写的文档转换成多种不同的格式,包括可打印的 PDF、epub 电子书以及自发布网页文档等。
作为 Github 的文档标记语言,markdown 已经为许多数据科学家所熟悉,因此 Bookdown 就成为整理文档资料,甚至出书排版的利器之一了。此外,它还支持多种不同的内核,也就是说它并不只限于 R 语言代码。
从2018年初开始,我就用 Bookdown 将我的技术博客转换成电子书的格式。对我来说,用 Bookdown 排版书籍可是比用 Latex 方便太多了,我之前论文用 Latex 的经历可真是不堪回首啊。
2. Cloud DataFlow
在 Google 云平台上,我最喜欢的工具之一就是 Cloud DataFlow。Cloud Dataflow 是 Google 提供的一项完全托管式的流式/批量数据处理服务,它提供了一个弹性而高可控的环境,让数据科学家可以在流水线运行时对其进行监控和问题排查。
在2018年,我试过在 DataFlow 上构建数据流水线、生产模型甚至进行游戏模拟等工作。总的来说,它的使用场景类似 Spark,但能更好的完成处理构建流式数据应用程序的任务。
此外,Dataflow 还可以被用作一个方便的集成点,通过向数据处理流水线添加基于 TensorFlow 的 Cloud Machine Learning 模型和 API,对类似的使用情形进行预测分析等进一步的深度学习数据处理,为机器学习夯实基础。
3. Python
以往的许多数据科学家,往往喜欢使用 R 语言,我也是如此。然而,近年来随着许多第三方库的出现,特别是机器学习、数据分析方面的第三方库日益完善,使用 Python 进行数据分析的软件生态链逐渐成为人们的第一选择。
在 Zynga,我的团队统一使用 Python 生态链上的各类分析工具。而在这之前,我对这种语言的接触不多。因此,我不得不强迫自己迅速接纳这门对我来说是全新的编程语言,还写下自己学习 Python 的动机,以及学习 PySpark、深度学习等新技术的愿望。
Python 的优势之一,就是社区提供了大量的第三方模块,使用方式与标准库类似。它们的功能覆盖科学计算、Web开发、数据库接口、图形系统多个领域。我们下面还会提到 Pandas、Featuretools 和 Flask 等。总的来说,Python 相当值得一学。
4. AWS Lambda
过去一年,我一直在关注如何让数据科学家能够将模型投入生产之中。而 AWS Lambda 等工具就提供了一个可行的解决方案。
AWS Lambda 是亚马逊提供的一个云代码托管服务,它让数据科学家能够在云中部署模型,进行实时数据流处理等工作。使用 Lambda,你可以指定一个函数,例如将预测模型应用于一组输入变量,然后 AWS 会处理部署这个函数,还提供了较好的弹性和容错能力。此外,你还可以使用 AWS Lambda 针对数据表中的每个数据更改,执行数据验证、筛选、排序或其他转换,并将转换后的数据加载到其他数据存储,能极大地简化模型部署工作。
5. Featuretools
Featuretools 库是用 Python 编写的一个自动化特征工程工具。
深度学习的一项重大创新,就是能够从半结构化数据(如文本文档)自动提取特征。而结构化数据集的特征工程技术也同样取得了质的飞跃。使用 Featuretools 库,你可以自动完成数据科学家在修改数据以构建预测模型时所执行的大部分工作。比如,它可以定义数据集中不同表(实体)之间的关联,还可以生成大量可应用于构建模型的特征等。我就尝试使用这种方法,利用脚本将北美冰球联赛的比赛自动分类为常规赛和季后赛。
6. Keras
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
2018年也是我终于开始接触深度学习的年份。我最初使用 Keras 的 R 语言接口来尝试构建深度学习模型,但后来转换到 Python 来使用这个库。由于我目前的工作主要是处理结构化数据集,因此目前还没有遇到很多必须使用深度学习来解决的情况,但总的来说,我发现使用自定义的损失函数还是非常有用的。
7. Flask
Flask 是一个使用 Python 编写的轻量级 Web 应用框架,你只需要编写一个简单的 python 文件就能变成一个全功能的 web 服务:
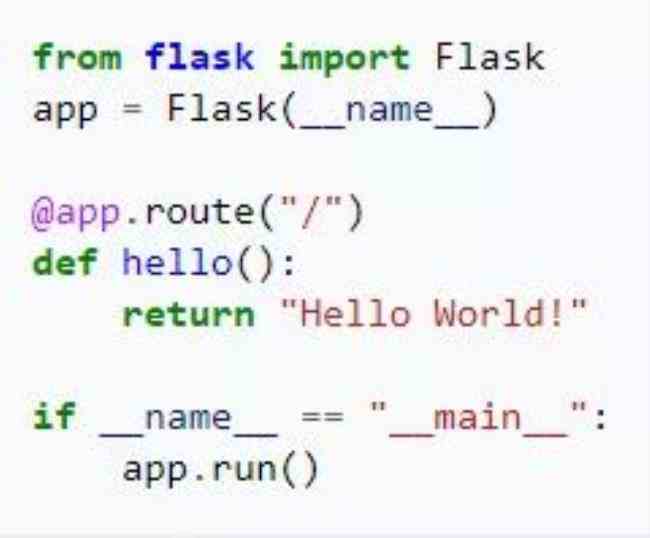
在学习 Python 之前,Jetty 是我构建 Web 服务的首选方法,毕竟我那时候用的是 Java。而 Flask 是一个用于将 Python 函数变为 Web 调用的神器,对于构建微服务非常有用。我试过使用 Flask 为深度学习分类器打造一个网页终端,而在GDC 2019 上,我还将向大家展示在公司里如何使用 Flask 和 Gunicorn 来构建一个微服务,方便内部使用。
8. PySpark
PySpark 是一个针对 Spark 的 Python API,它能让你用 Python 语言处理 Spark 的“弹性分布式数据集”(resilient distributed dataset)RDD 对象。
在过去的一年里,我使用 PySpark 完成了越来越多的工作,一是因为它可以处理相对庞大的数据集,二是因为一旦你熟悉了 Python,使用 PySpark 就非常容易。如果你也想开始学习 PySpark,你可以使用 Databricks 社区版来启动和运行 Spark 环境,这很简单。
9. Pandas UDFs
并非所有 Python 代码都可以直接在 PySpark 里用,但是 Pandas UDF 使得在 Spark 中重用 Python 代码变得更加容易。 使用 Pandas 的用户定义函数(UDF,User-Defined Function),我们可以在函数中使用 Pandas 数据表对象,并指定用于拆分数据表的 key。结果就是,一个巨大的 Spark 数据表可以在分配给集群中的各个节点,转换为可以被你的函数所操作的 Pandas 数据表,然后将结果组合回原来的 Spark 表。这意味着我们可以在分布式模式下使用现有的 Python 代码。我目前供职的 Zynga 公司就使用 Pandas UDF 来构建预测模型。
10. 开放数据集
在过去一年中,为了撰写有关数据科学的文章,我从许多开放数据集里获得示例数据。我使用的实例里,就包括了来自 Kaggle、BigQuery 以及政府开放数据集的数据。
2018年是学习新数据科学技术的好年头,我很高兴能在新的一年里继续学习。在2019年,我期待着探索强化学习技术,Spark Streaming 在线机器学习技术以及用深度学习技术处理半结构化数据库等全新的领域。让我们一起学习吧!
有话要说...